
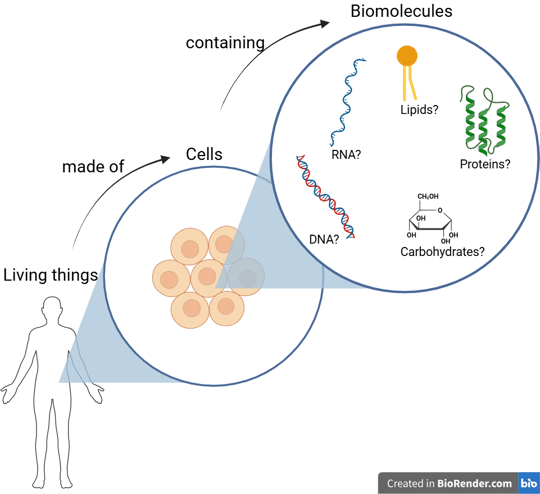
Biomolecules
What is life made of on the Earth?
When we look around the planet we live on, we can observe a wide variety of living things. They may appear very different from one another, yet they all share certain fundamental properties — such as the ability to grow, reproduce, and eventually die.
You may wonder: What is life made of? And what determines the properties of living organisms?
If we use an optical microscope to examine the tissues of living things, we see that they are made up of many small, individual units. In biology, we call these cells — the basic unit of all living organisms.
However, from a chemist’s perspective, cells are not the ultimate answer. Chemists focus on the substances that make up cells — the molecular building blocks of life.
Let’s imagine that we have a super-powerful magnifier that allows us to zoom in even further, deep inside the cell. There, we would find a variety of molecules — including nucleic acids (DNA and RNA), proteins, lipids, and carbohydrates.
These four types of molecules are known as the fundamental biomolecules — the essential components shared by all living organisms.
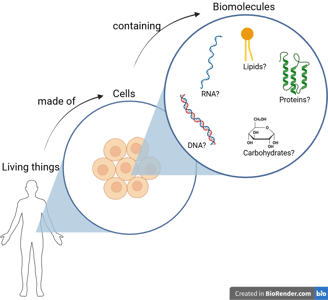
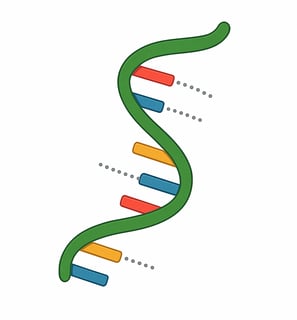
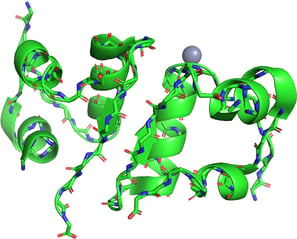
Although there are four main types of biomolecules, molecular biology primarily focuses on nucleic acids (DNA and RNA) and proteins, because these molecules are directly responsible for storing, transmitting, and expressing genetic information — the fundamental processes that define life at the molecular level.



Carbohydrates and lipids are also essential to life, but they mainly play structural and metabolic roles. In contrast, nucleic acids serve as the blueprints, and proteins act as the machinery of the cell.
That’s why this section will focus specifically on DNA, RNA, and proteins.
Deoxyribonucleic Acid (DNA)
DNA (deoxyribonucleic acid) is a long, double-stranded molecule that stores the genetic instructions used in the development and functioning of all living organisms.
The discovery of DNA happened gradually, through many key moments in science.
In 1869, Swiss physician Friedrich Miescher isolated a new substance from the nuclei of white blood cells. He found that this material was rich in phosphorus and called it "nuclein."
At the time, nobody knew that nuclein played an important role in heredity — it was considered merely a chemical curiosity.
However, we now know that nuclein is actually DNA (deoxyribonucleic acid), and Miescher was the first person to isolate this fundamental molecule.
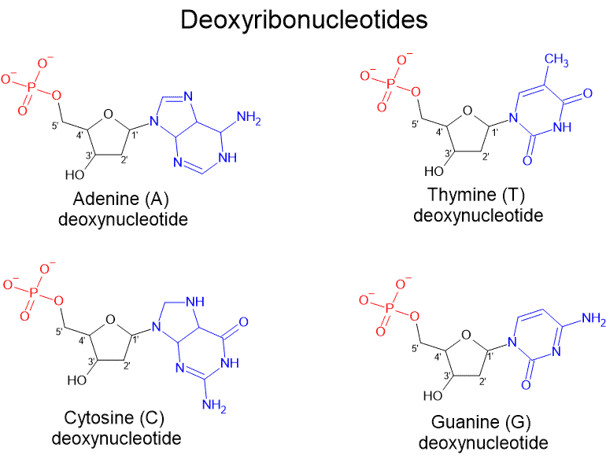
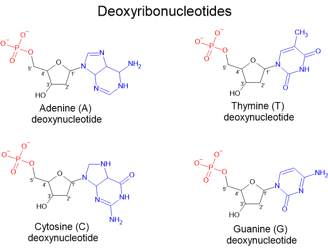
During the late 1800s and early 1900s, various scientists — including Phoebus Levene — tried to figure out what nuclein was made of. Through their studies, they found that nucleic acids are composed of smaller units called nucleotides, which are the building blocks of DNA. Each nucleotide consists of a sugar, a phosphate group, and a nitrogenous base.
A deoxyribonucleotide consists of:
A phosphate group (shown in red),
A five-carbon sugar, specifically deoxyribose (shown in black), and
One of four nitrogenous bases (shown in blue):
Adenine (A), Thymine (T), Cytosine (C), or Guanine (G).
In deoxyribonucleotides, which make up DNA, the phosphate group is attached to the 5' carbon of deoxyribose. Notably, unlike ribose (found in RNA, which we will discuss later), deoxyribose lacks an oxygen atom at the 2' carbon — which is why it is called "deoxy."
During the 1930s - 1950s, William Astbury suggested that DNA had a regular, stacked structure.
Rosalind Franklin and Maurice Wilkins provided the proof from X-ray diffraction to confirm DNA was helical, highly ordered and regular over long distances.
DNA is a long polymer chain like plastic.
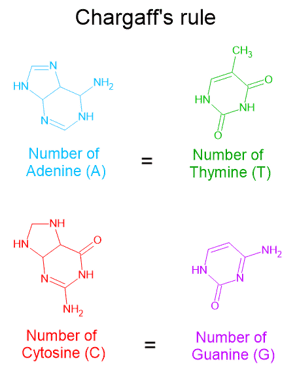
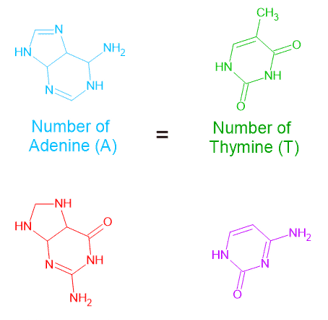
There was a critical turning point in 1950. Erwin Chargaff found that
the proportion of A+T vs. G+C varied widely among species.
the ratios of A : T and G : C were equal in every species → Chargaff’s Rules.
DNA was not repetitive, but had variable sequences of nitrogenous bases.
Although he did't suggest pairing, but his discovery strongly hinted that bases are somehow paired in DNA, and opened the door to thinking of DNA as a code.
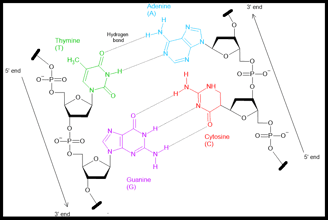
The Final and Correct Model of standard DNA's Structure
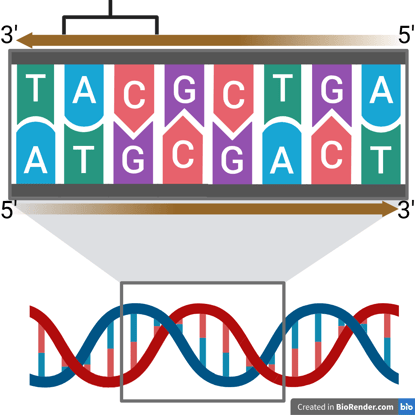
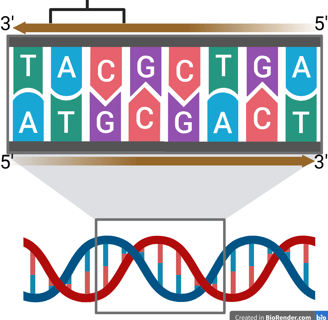
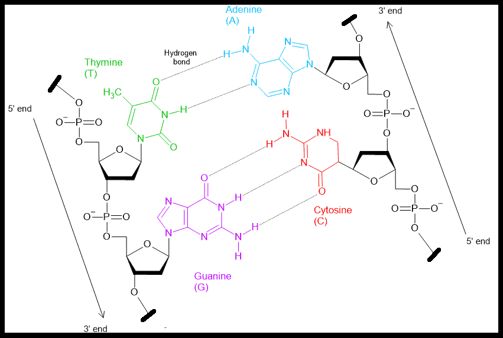
In 1953, James Watson and Francis Crick, working at the University of Cambridge, proposed the now-famous double helix model of DNA. Their breakthrough was based in part on X-ray diffraction data collected by Rosalind Franklin and Maurice Wilkins.
Watson and Crick’s model revealed that DNA is made of two complementary strands twisted into a helix, with base pairs (A–T and G–C) forming the rungs of a twisted ladder. The bases pair through hydrogen bonds:
Adenine (A) pairs with Thymine (T) via two hydrogen bonds
Cytosine (C) pairs with Guanine (G) via three hydrogen bonds
These base-pairing rules help explain Chargaff’s rule, which observed that the amount of A equals T, and C equals G, in any DNA sample.
The double helix is also anti-parallel, meaning that one strand runs in the 5′ → 3′ direction, while the complementary strand runs in the 3′ → 5′ direction. Watson and Crick’s model specifically described the B-form DNA, which is right-handed.
You can visualize this by holding up your right hand with your thumb pointing upward. Your thumb represents the axis of the DNA helix, and your curled fingers show the direction in which the strands twist around it—clockwise when viewed from above, just like B-DNA.
Why is it so important?
This elegant structure showed how DNA could carry encoded biological information as genetic material. The sequence of base pairs acts like a language — much like binary code in computers (e.g., 01010...) — but using A, T, C, and G instead of 0s and 1s. In essence, DNA stores the genetic instructions that direct the growth, development, and function of all living organisms.
Watson and Crick’s model explained how DNA could be:
Faithfully copied during cell division
Decoded to build proteins
And serve as the blueprint of life
Their discovery laid the foundation for the field of molecular biology and revolutionised our understanding of heredity, evolution, and genetics.
References:
Maderspacher, F. (2004). Rags before the riches: Friedrich Miescher and the discovery of DNA. Current Biology, 14(15), R608.
Levene, P. (1919). THE STRUCTURE OF YEAST NUCLEIC ACID. Journal of Biological Chemistry, 40(2), 415–424.
Pray, L. (2008). Discovery of DNA double helix: Watson and Crick | Learn Science at Scitable. Nature Education. https://www.nature.com/scitable/topicpage/discovery-of-dna-structure-and-function-watson-397/
Levene, P., & London, E. (1929). THE STRUCTURE OF THYMONUCLEIC ACID. Journal of Biological Chemistry, 83(3), 793–802.
Astbury, W. T., & Bell, F. O. (1938). SOME RECENT DEVELOPMENTS IN THE X-RAY STUDY OF PROTEINS AND RELATED STRUCTURES. Cold Spring Harbor Symposia on Quantitative Biology, 6(0), 109–121.
Franklin, R. E., & Gosling, R. G. (1953). Molecular configuration in sodium thymonucleate. Nature, 171(4356), 740–741.
Wilkins, M. H. F., Stokes, A. R., & Wilson, H. R. (1953). Molecular structure of nucleic acids: Molecular structure of deoxypentose nucleic acids. Nature, 171(4356), 738–740.
Watson, J. D., & Crick, F. H. C. (1953). Molecular structure of nucleic acids: A structure for deoxyribose nucleic acid. Nature, 171(4356), 737–738.
Ribonucleic Acid (RNA)
When chemist Phoebus Levene studied nucleic acids in the early 1900s, he found not only deoxyribonucleic acid (DNA) but also ribonucleic acid (RNA).
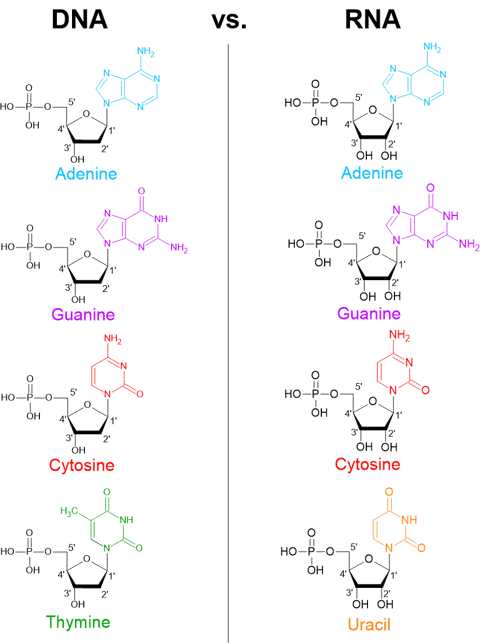
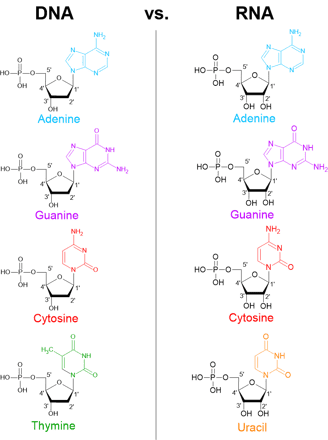
We can see that the monomeric nucleotides of DNA and RNA are very similar, but they have slight differences.
RNA contains ribose, which has a hydroxyl group (-OH) at the 2′ carbon, while DNA contains deoxyribose, which lacks that oxygen atom at the same position.
RNA also contains four nitrogenous bases but one of the four bases is uracil (U) rather than thymine (T).
Unlike DNA, RNA is typically single-stranded in cells. RNA is also less chemically stable than DNA, which helps ensure its temporary role in cells.
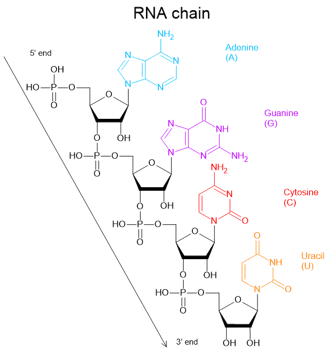



In the late 1950s, scientists suspected that an unstable temporary substance carried genetic information from DNA to ribosomes, and proposed that the substance was RNA.
In 1961, François Jacob & Jacques Monod, with Sydney Brenner and Matthew Meselson used bacteriophage-infected E. coli to show that newly made RNA directed the synthesis of phage proteins. These demonstrated the existence of messenger RNA (mRNA) as the transient copy of genetic information.
As we can see, DNA and RNA share similarities, so it is not hard to understand that both can carry genetic information by encoding the sequence of nitrogenous bases.


References:
Brenner, S., Jacob, F., & Meselson, M. (1961). An Unstable Intermediate Carrying Information from Genes to Ribosomes for Protein Synthesis. Nature, 190(4776), 576–581.
R. Giegé, J. D. Puglisi and C. Florentz, tRNA Structure and Aminoacylation Efficiency, Prog Nucleic Acid Res Mol Biol, 1993, 45, 129–206.
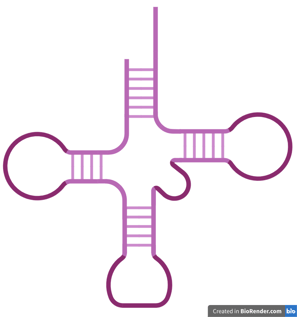
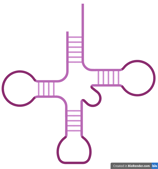
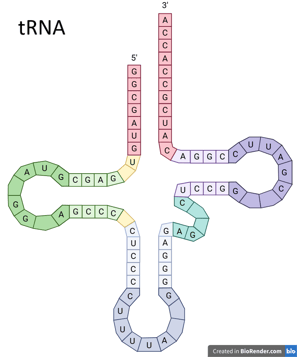
Similar to DNA, each of the nitrogenous bases can also hybridise with a complementary base.
Adenine (A) pairs with Uracil (U) or Thymine (T)
Cytocine (C) pairs with Guanine (G)
This means that RNA can hybridise with a complementary DNA or RNA strand. This hybridisation is important in processes like transcription and RNA-based technologies that we will discuss in gene expression and molecular biology techniques later.
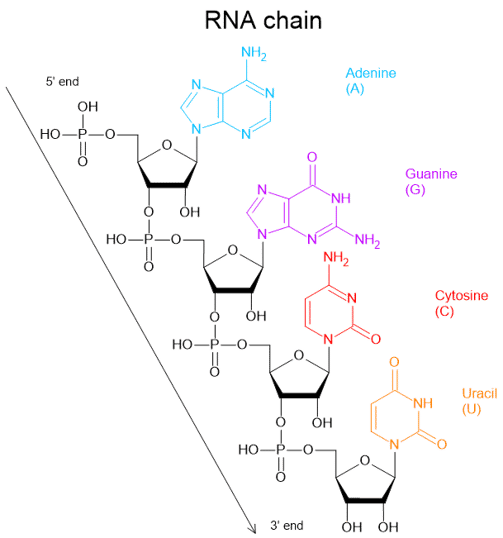
Since RNA is single-stranded, it has a greater ability to fold and coil into various conformations. RNA chains can fold into specific three-dimensional structures through intramolecular interaction, including the hybridisation between A and U as well as C and G. This allows RNA to take on many different functions, depending on its structure and type. tRNA in the left figure is one of the examples.
tRNA: cloverleaf shape, brings amino acids to ribosomes
mRNA: single-stranded messenger"
Monomers of DNA and RNA
RNA (ribonucleic acid) is a single-stranded molecule that plays diverse roles in cells, including carrying genetic messages, building proteins, and regulating gene expression.
Proteins
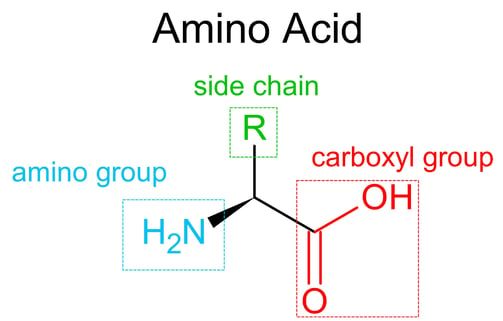
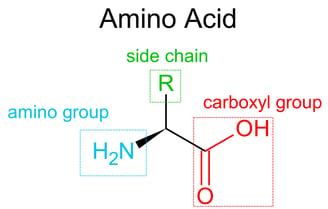
Proteins are large, complex molecules made from chains of amino acids. They are essential for nearly every structure and function in living organisms.
The discovery of proteins is a long story, but there were a few key moments to reveal the secrets of this catagory of biomolecules.
In the 18th – early 19th century, scientists proposed that proteins were nitrogen-rich and a new class of biological molecule, distinct from carbohydrates and fats.
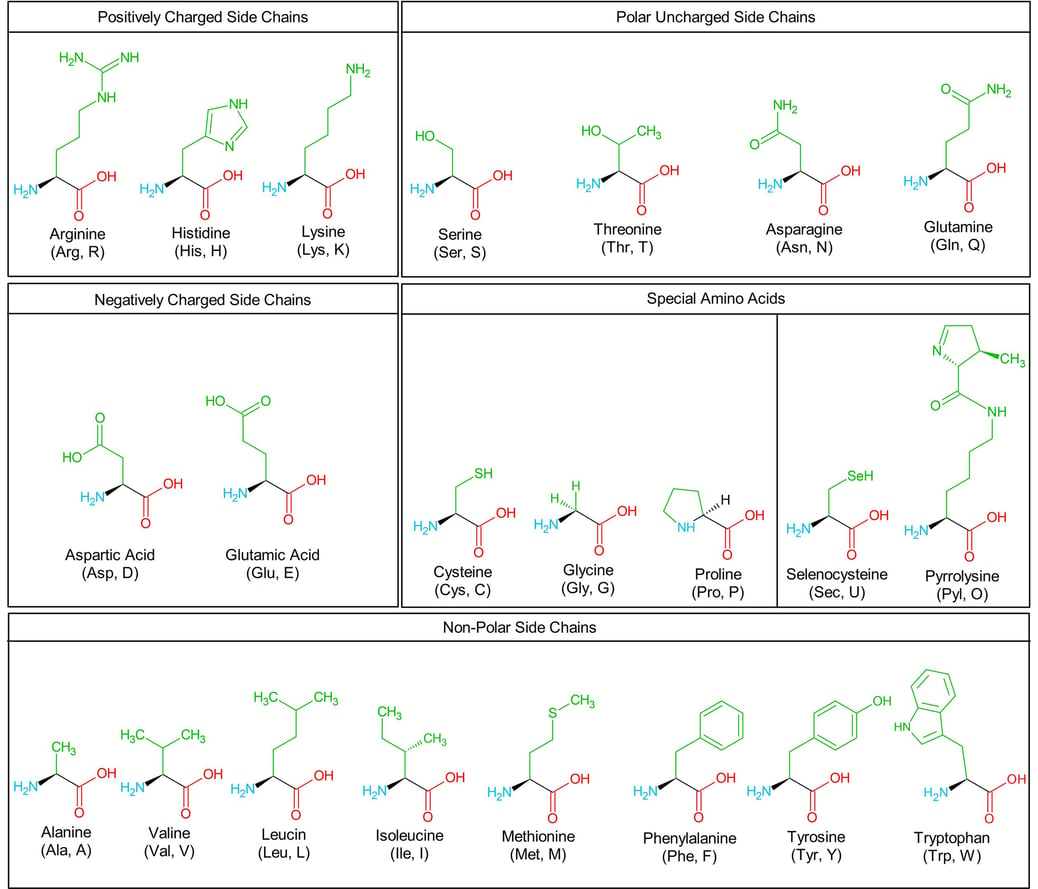
Over the 19th century, the building blocks of proteins, amino acids, were gradually discovered one by one. The following chart exhibits the structure of 22 amino acids that are encoded by the genetic code of eukaryotes.
References:
All about amino acids, https://www.jpt.com/support-contact/resources/amino-acids/.
E. Fischer, Untersuchungen über Aminosäuren, Polypeptide und Proteine II (1907–1919), 1923.
F. Sanger and H. Tuppy, The amino-acid sequence in the phenylalanyl chain of insulin. 2. The investigation of peptides from enzymic hydrolysates, Biochemical Journal, 1951, 49, 481–490.
Khan Academy, https://www.khanacademy.org/science/biology/macromolecules/proteins-and-amino-acids/a/orders-of-protein-structure.
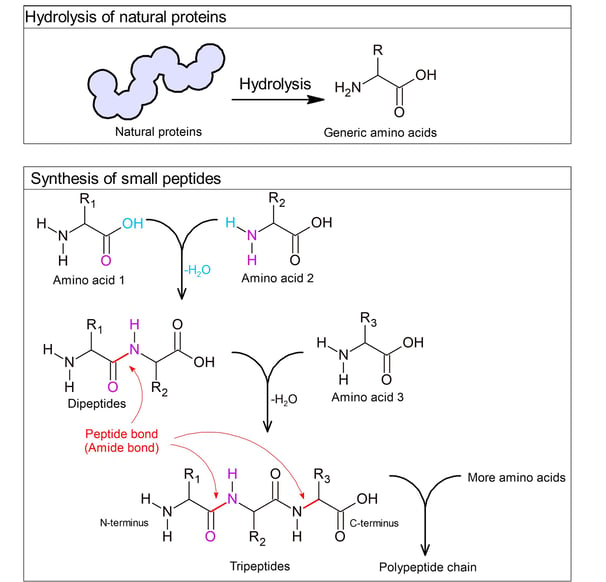
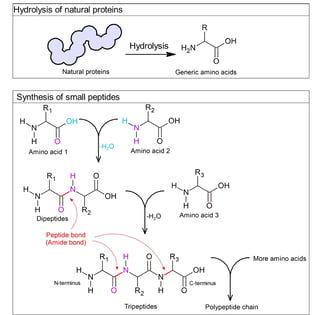
Until the early 1900s, chemist Emil Fischer introduced the term "peptide" and suggested that proteins were polypeptides.
He hydrolysed natural proteins by breaking them down using acids or enzymes, and consistently obtained amino acids as the breakdown products.
He also chemically synthesised small peptides (dipeptides, tripeptides, and longer chains of polypeptides) using acid chloride-activated carboxylic acid group of one amino acid. It could react with the amine group of another, forming an amide bond that he called a peptide bond.
These demonstrated that proteins are made of amino acids linked by peptide bonds.
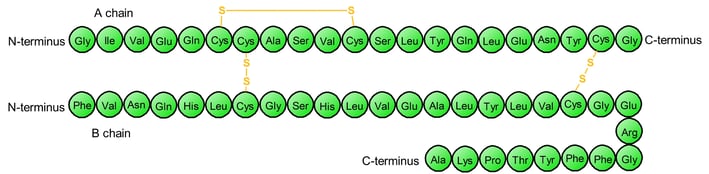

The amino acid sequence of bovine (cow) insulin, determined by Frederick Sanger in 1955, was the first to reveal that proteins are made of precisely ordered amino acids — a concept now known as primary structure.
Sequence of bovine (cow) insulin (adapted from 3)
But the primary structure is just the beginning👻! Proteins don't function as straight chains — they fold into complex 3D shapes, forming secondary, tertiary, and sometimes quaternary structures, which determine their final shape and function.


Secondary Structure
Let's imagine beads on a string. It is a chain of beads with random conformation, like jewellery you see in reality.
Now imagine that some of the beads represent parts of the protein backbone capable of forming hydrogen bonds — just like magnetic beads that attract each other.
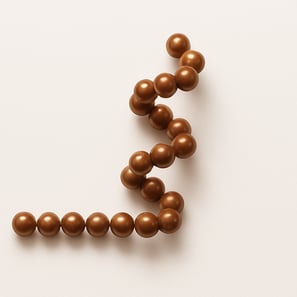
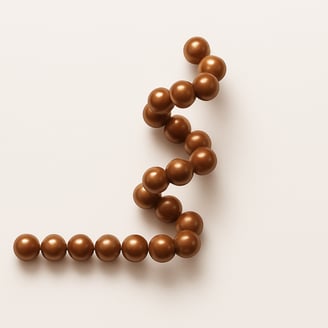
Magnetic beads will attract and stick together, causing parts of the string to fold or curl. The conformation may be like this because of the intra-string attraction.
In a polypeptide chain, the backbone has a lot of amide groups that can form intramolecular hydrogen bonds. These hydrogen bonds are like the magnetic attraction between the beads on a string, driving the local folding of the chain. Alpha helix (α-helix) and beta sheet (β-sheet) are two main types of secondary structures.
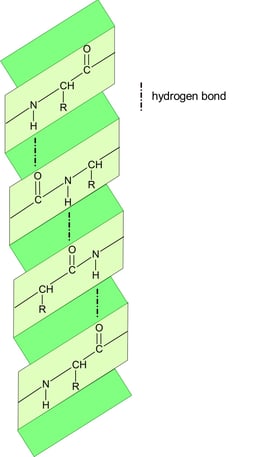
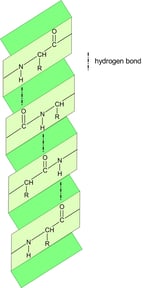


There are other secondary elements
beta-turns/hairpins: Sharp bends that reverse the direction of the chain and are often found connecting strands of a beta sheet.
Loops and Coils: Irregular, flexible regions that connect helices and sheets are often found on protein surfaces, where they interact with other molecules.


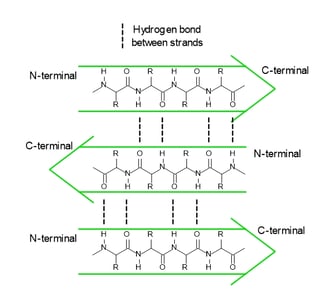
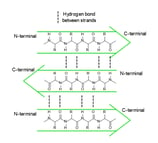


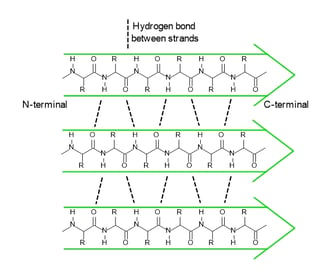
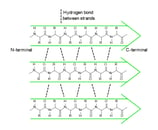
α-helix
anti-parallel β-sheet
parallel β-sheet
Tertiary Structure
We explored the local structure, but how about the whole structure of a polypeptide?
Remember that each amino acid in a polypeptide has a unique side chain (R group)👻?
After forming local structures like alpha-helices and beta-sheets, the entire polypeptide chain folds into its overall 3D shape, which is a functional form.
It is determined by the interactions between side chains (R groups) of the amino acids, not just the backbone like in secondary structure.
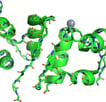
I chose hen egg-white lysozyme as an example. I used the data from the RCSB Protein Data Bank (PDB) and exhibited it using PyMOL.
We can see this single polypeptide chain containing α-helices, β-sheets, irregular loops, and coils as local structures. These parts fold into a specific 3D shape to form a functional protein.
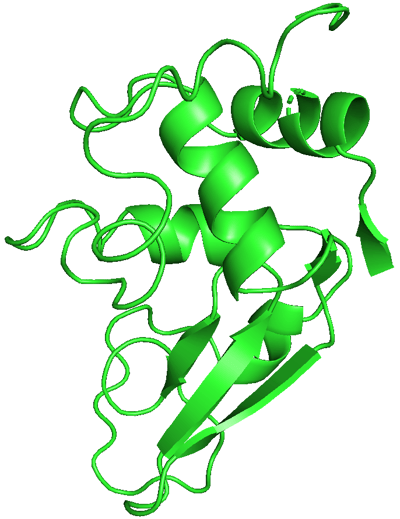
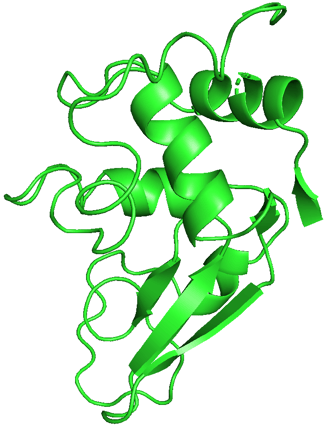
Demonstration of hen egg-white lysozyme structure using PyMOL.
PDB ID: 1LYZ
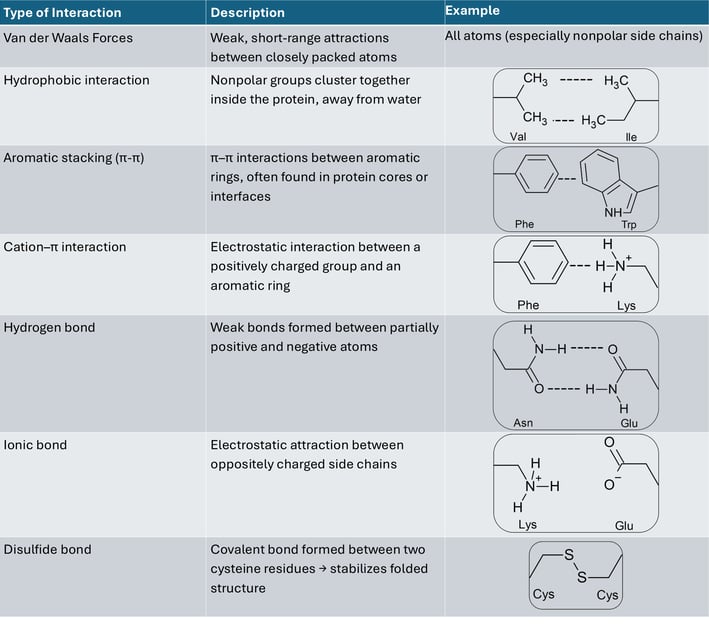
Table of interactions between side chains
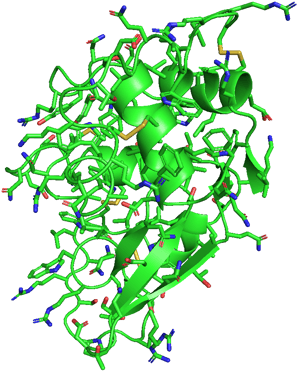
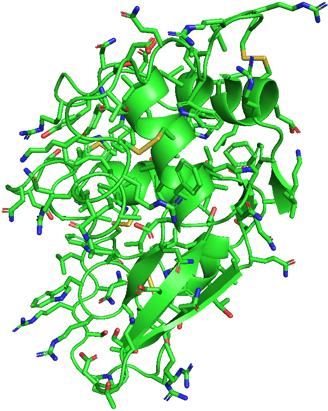
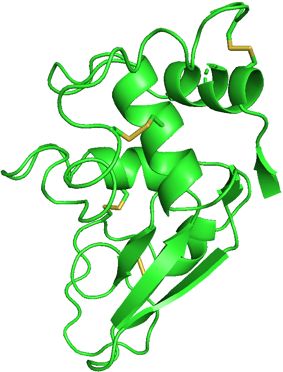
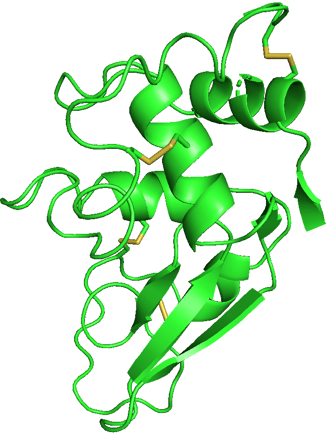
If I show you the side chains of the protein, it will be really complicated. Don't panic! I selected to show only disulfide bonds (yellow) in another figure. It is already enough to help you understand the effect of side chains.
As we know, the side chain of a cysteine is a thiol group (-SH). A disulfide bond can be formed between two thiol groups of the two cysteine amino acids. It means that the locations of cysteine determine the location of disulfide bonds, causing the polypeptide chain to fold into a specific structure to form these bonds.
To look back at all the side chains, the sequence of amino acids determines where and how the interactions of side chains occur. Like the interactions on the table, these interactions work together to fold the polypeptide from its linear chain into a compact, stable 3D shape — the tertiary structure, which is essential for the protein’s specific function.
Structure of 1LYZ with side chains
Structure of 1LYZ with disulfide bonds only
Table of the structure of 22 amino acids that are encoded by the genetic code of eukaryotes.
Quaternary Structure
Quaternary structure is the 3D arrangement of two or more polypeptide chains (subunits) that come together to form a single, functional protein complex.
Components of LEGO with different tertiary structures
Quaternary structure of LEGO
Polypeptides are like the LEGO of life. A protein can be made of more than one component. The formation of a protein complex driven by the same types of interactions as tertiary structure, but now occurs between separate chains, not within one.
Tertiary: folding of one chain
Quaternary: multiple folded chains assembled
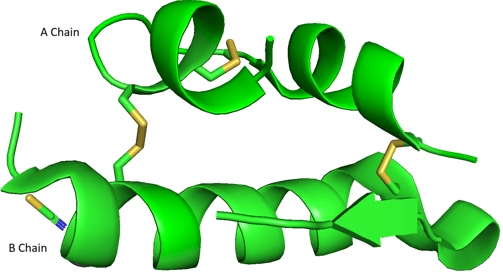
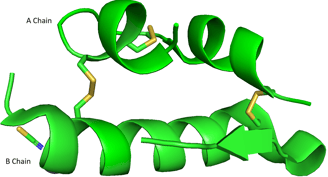
Please take a look at the abovementioned bovine insulin again. A and B chains are two separate polypeptide chains, but they stick together because of two disulfide bonds (yellow). The A and B chains are two distinct polypeptides, held together by disulfide bonds — an example of quaternary structure.
After you learn the concepts of primary, secondary, tertiary, and quaternary structures, you should be able to understand the 3D structure of bovine insulin. The real 3D image of A and B chains should be like this.
Sequence of bovine (cow) insulin (adapted from 3)
Demonstration of bovine insulin A and B chains using PyMOL.
PDB ID: 4E7U
Primary Structure: Linear amino acid sequence of A and B chains.
Secondary Structure: Local structures like α-helices and β-sheets within A and B chains.
Tertiary Structure: The 3D fold of each A chain, and each B chain, including the intra-chain disulfide bond in A.
Quaternary Structure: The association of the A and B chains via inter-chain disulfide bonds.
These are also observed in various proteins in our world.
➡️Different sequences
➡️Different folding mechanisms
➡️Different 3D structures
➡️Different proteins
➡️Different proteins
➡️Different biological functions
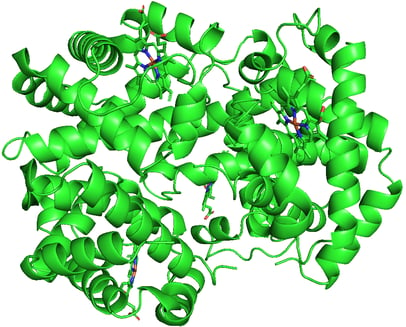
Hemoglobin. PDB ID: 1A3N
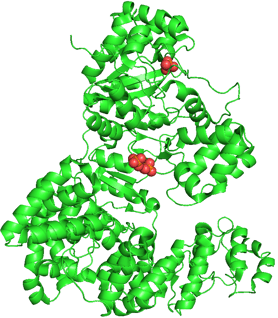
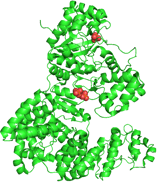
DNA polymerase III. PDB ID: 2HNH
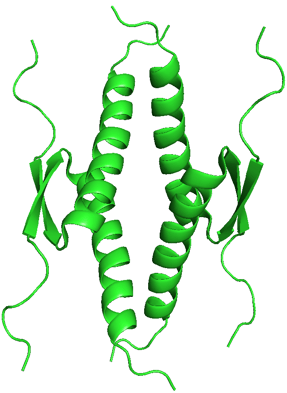
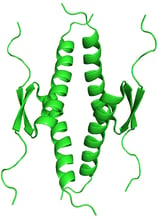
p53 Tumor Suppressor. PDB ID: 1OLG
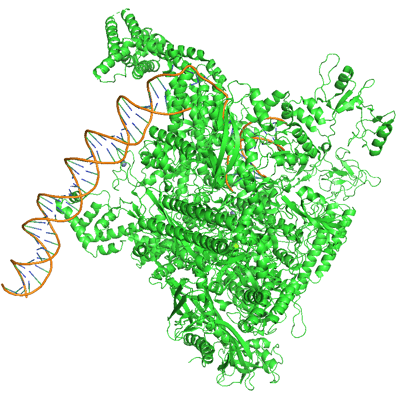
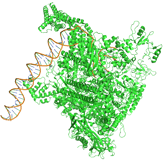
RNA Polymerase. PDB ID: 6CA0
A protein’s 3D structure is like its tool shape — it fits with specific targets and performs specific tasks. Different shapes mean different roles.
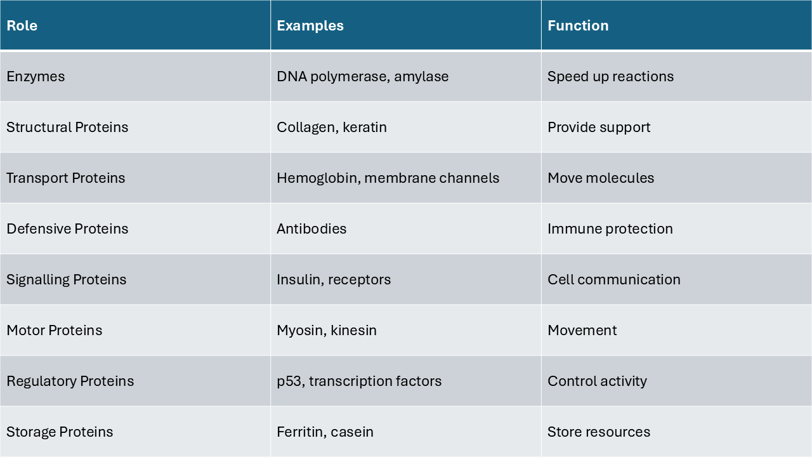
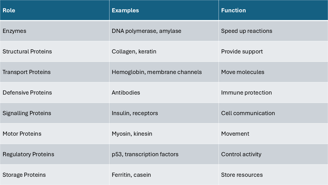
This table summarizes key roles proteins play in cells, matched with real-life examples.
© 2025 Anson Chow. All rights reserved.
Keep exploring, learning, and thinking.
Driven by curiosity, guided by strategy, fueled by passion.