
The Flow of Genetic Information
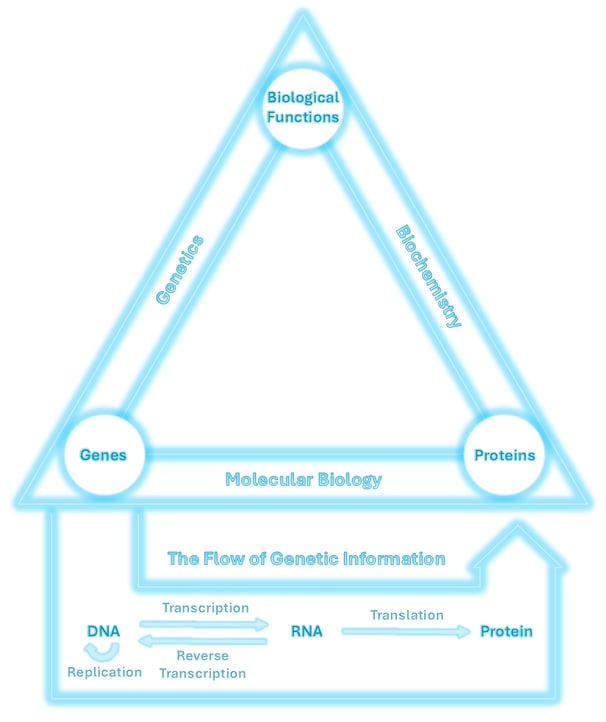
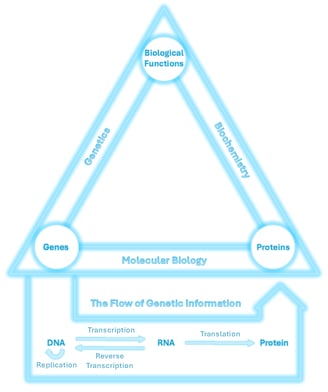
The relationship between genes, proteins, and biological functions is central to life. These three elements are connected through the scientific disciplines of genetics, molecular biology, and biochemistry, as shown in the triangle above.
This page is part of my personal study strategy🌠, inspired by the idea of a “Theory of Everything” in physics, a unifying overview that ties together an entire field. Here, I’ve created a conceptual framework to represent the core logic of life science, focusing on the flow of genetic information between DNA, RNA, and proteins.
This flow forms the foundation of molecular biology and illustrates how life works at the molecular level, from genetic instructions to functional outcomes.
⭐Before we dive into this page, let’s quickly revisit a key concept about biomolecules from earlier.
We learned that proteins have specific shapes that allow them to bind to precise targets and carry out specific tasks. One important class of proteins is enzymes, which catalyse chemical reactions by interacting with particular molecules.
Meanwhile, DNA acts like a storage system for information — much like a computer stores digital code. On this page, you’ll discover how enzymes (which are proteins) act like molecular workers, reading and executing the instructions encoded in DNA.
1.DNA Replication
I am building my website, which is launching soon.
Come back and check it out.
At the beginning of life, each of us started as a single fertilised egg, one cell carrying the full set of genetic instructions that would guide our growth. This blueprint, stored in DNA inside the cell nucleus, controls how cells divide, develop, and function.
As that one cell divides to form two, four, and eventually trillions of cells, it must copy its DNA each time. This process is called DNA replication — it ensures that every new cell inherits the exact same genetic information. Without it, life as we know it wouldn't be possible.
1.1 Initiation
DNA replication begins at specific DNA sequences known as origins of replication.
These sites are typically A–T rich regions, which are easier to unwind due to having only two hydrogen bonds per pair (compared to three in G–C pairs).
Eukaryotic chromosomes are large and linear. Because of their size, it’s inefficient and too time-consuming to replicate the entire chromosome from a single site. Therefore, eukaryotes have multiple origins of replication distributed across their chromosomes.
In contrast, prokaryotic chromosomes are smaller and circular. They typically contain only one origin of replication on their main chromosome.
Origin of Replication



Initiator proteins are responsible for determining where and when DNA replication begins. Their main role is to recognise and bind to specific origin sequences, thereby marking the starting point for DNA synthesis.
In eukaryotes, key initiator proteins include the Origin Recognition Complex (ORC), Cdc6, and Cdt1.
In prokaryotes, the initiator is DnaA.
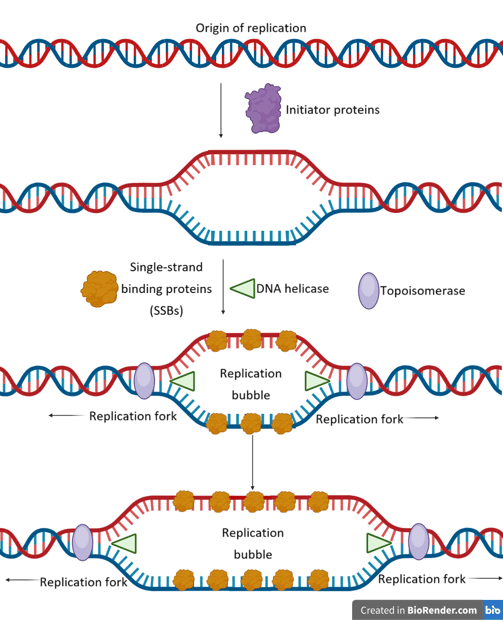
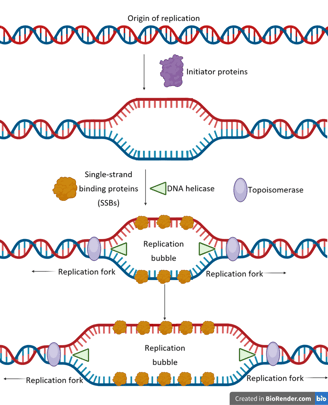
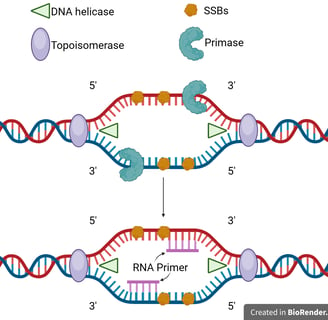
Initiator proteins bind to the origin, causing local DNA unwinding — a small “melting” of the double helix — forming a replication bubble.
These proteins act as a landing pad for the enzyme helicase, which unwinds the DNA further by breaking hydrogen bonds at the replication forks.
Single-strand binding proteins (SSBs) coat the exposed DNA strands to prevent re-annealing and protect them from degradation.
As helicase moves forward, it introduces torsional strain ahead of the fork. Topoisomerase (e.g., DNA gyrase in prokaryotes) relieves this strain by cutting, unwinding, and rejoining DNA strands.
1.2 Elongation
Enzymes in Initiaton
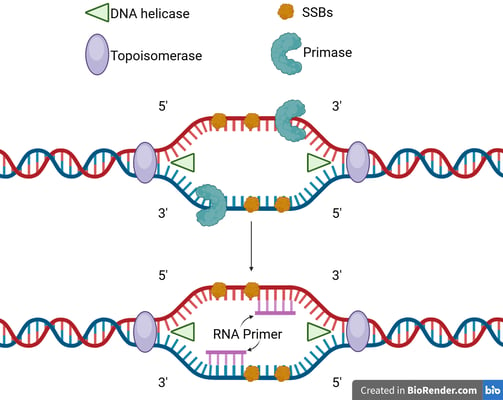
DNA polymerase cannot initiate DNA synthesis from scratch; it requires a pre-existing 3'-hydroxyl group to add nucleotides.
This is provided by a short RNA segment called an RNA primer, synthesised by an enzyme called DNA primase. A primer is laid down at the origin for the leading strand.
⭐In eukaryotes, the RNA primer will be further extended by DNA polymerase alpha (Pol α) before replication. The primer in eukaryotes is short RNA-DNA primer.
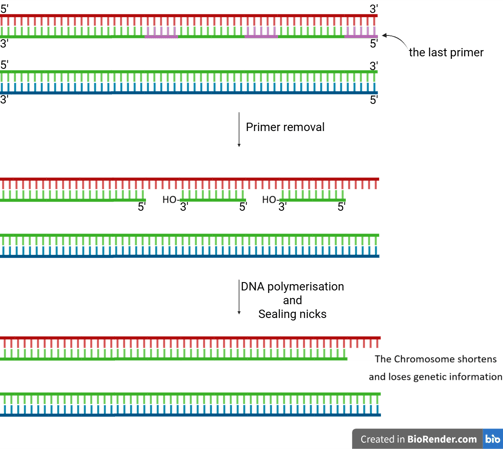
Primer Removal
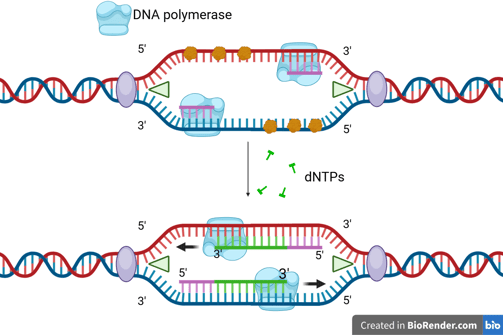
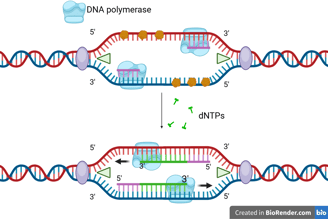
One of the template strands is oriented in the 3' to 5' direction towards the replication fork. On this leading strand, DNA polymerase can synthesise the new DNA strand in the 5' to 3' direction, moving towards the replication fork.
Leading Strand Synthesis
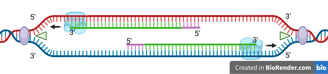
The DNA helicase and DNA polymerase keep moving to synthesise the new DNA strand continuously. Only one RNA primer is needed for the leading strand.
When the DNA helicase and DNA polymerase on the leading strand move away from the origin in the same direction, the opposite strand has not been replicated.
Primase works again to synthesise new primers on the lagging template as new single-stranded regions become available.
Lagging Strand Synthesis
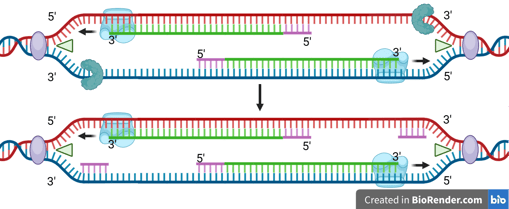
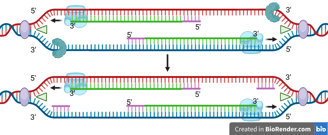
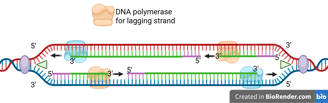
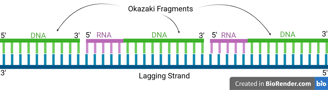
Because DNA polymerase can only synthesise in the 5' to 3' direction, this strand must be synthesised discontinuously in short fragments called Okazaki fragments.
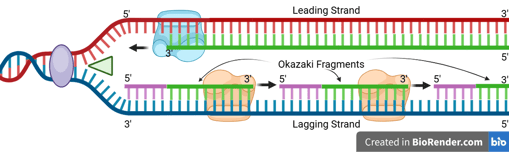
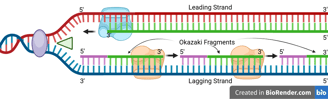
For each Okazaki fragment, DNA primase synthesises a new RNA primer. The DNA polymerase on the lagging strand then extends this primer, adding DNA nucleotides in the 5' to 3' direction until it reaches the next RNA primer.
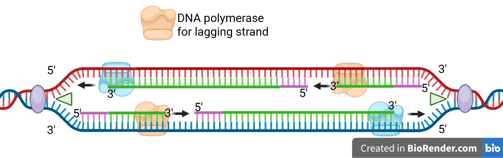
Note that there are different kinds of DNA polymerases for leading strand and lagging strand syntheses in eukaryotes and prokaryotes.
In eukaryotes:
DNA Epsilon (Pol ε): responsible for synthesising leading strands.
DNA Delta (Pol δ): responsible for synthesising lagging strands.
In prokaryotes:
DNA polymerase III: responsible for synthesising both leading and lagging strands.
⭐Let us zoom in on the lagging strand in eukaryotes and prokaryotes. We will realise some problems.
While we want to replicate a complete DNA copy from the template, the primers are made of RNA, and the lagging strands are discontinuous.
How are these problems solved to create a complete DNA strand?
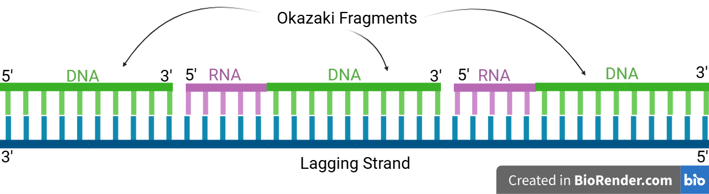
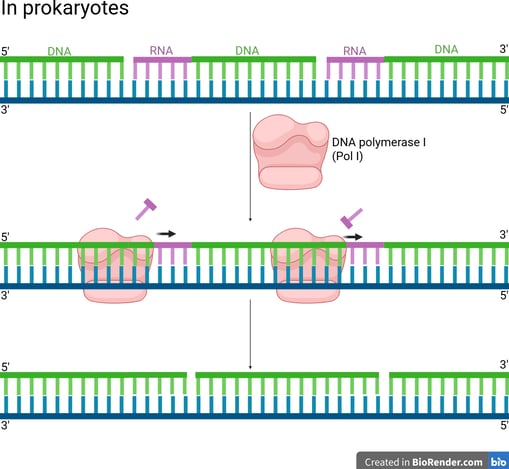
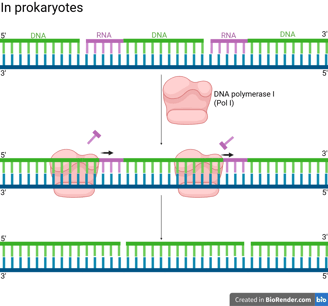
In prokaryotes (e.g. bacteria), DNA Polymerase I (Pol I) has the following properties to achieve primer removal.
5' to 3' Exonuclease Activity: Pol I moves along the DNA and continuously removes the RNA nucleotides starting at the 5' end of the RNA primer of the downstream Okazaki fragment by hydrolysing the RNA primer.
Polymerase Activity (Gap Filling): Pol I simultaneously synthesises DNA to fill the gap left by the removed primer.
Conclusively, the overall result is that Pol I replaces RNA primers with DNA.
Notes that even after Pol I's action, the lagging strand is still discontinuous because the Okazaki fragments are not covalently linked together yet. Pol I fills the gap but leaves a final phosphodiester bond missing (a "nick").
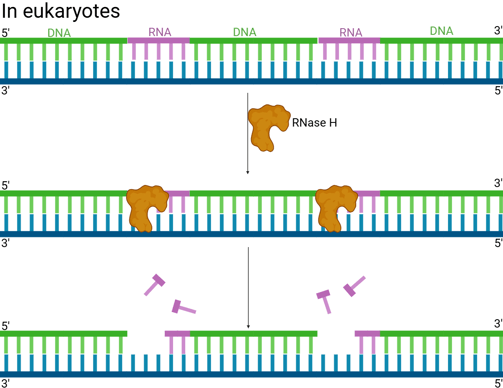
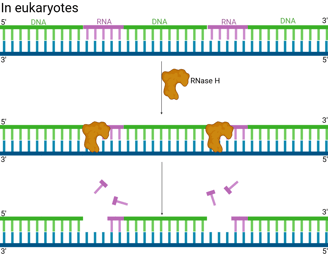
In eukaryotes (e.g. humans), the removal of RNA is more complicated.
RNase H is an enzyme that recognises the hybrid structure formed when the RNA primer is base-paired to the DNA template. It specifically degrades RNA within an RNA-DNA hybrid by hydrolysing the phosphodiester bonds.
RNase H usually leaves behind one or a few ribonucleotides (often the very last one) attached to the 5' end of the newly synthesised DNA of the Okazaki fragment. It often can't completely remove the RNA right up to the RNA-DNA junction.
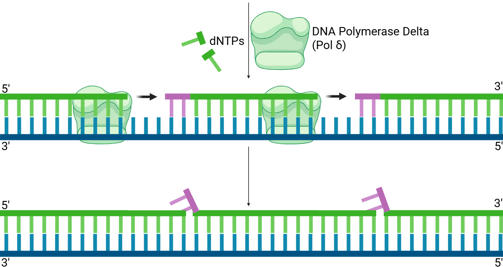
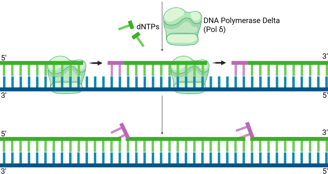
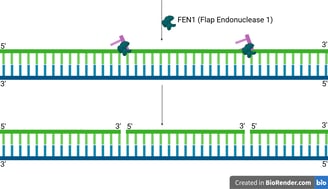
DNA Polymerase Delta (Pol δ), which extends the lagging strand and synthesises most of the Okazaki fragment, continues its synthesis.
As Pol δ encounters the remaining RNA nucleotides or the start of the upstream Okazaki fragment, its strand displacement activity comes into play. It pushes forward, displacing the remaining RNA primer (and sometimes a few DNA nucleotides from the previous Okazaki fragment) into a single-stranded "flap" structure. This flap typically has a 5' end containing the last one or two ribonucleotides, followed by the DNA sequence.
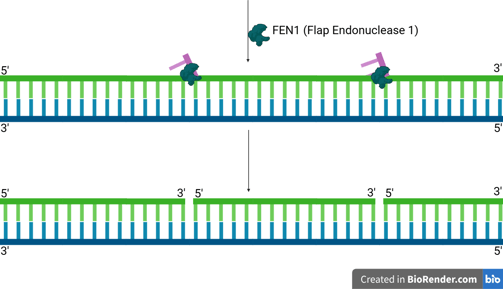
FEN1 is a structure-specific endonuclease. It recognises these 5' single-stranded DNA or RNA-DNA flaps.
FEN1 then precisely cleaves the phosphodiester bond at the junction, removing the entire flap (which contains the remaining RNA primer and any displaced DNA).
sealing nicks (gaps)
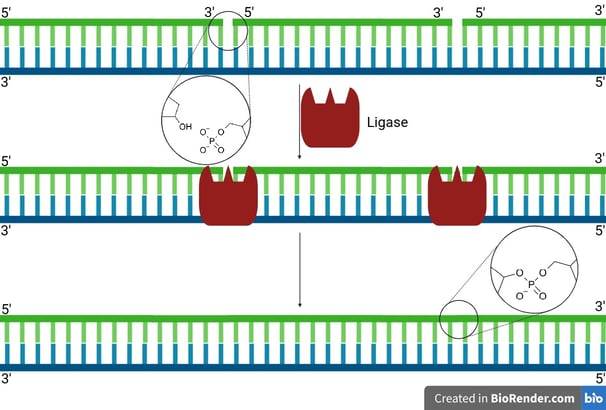
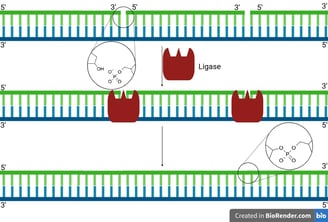
After primer removal and gap filling by DNA polymerase, a small nick remains:
There’s a free 3'-OH on one DNA fragment.
And a 5'-phosphate on the next fragment.
But no phosphodiester bond joining them.
DNA ligase binds at this nick site and uses ATP (in eukaryotes) or NAD⁺ (in prokaryotes like E. coli) to activate the 5'-phosphate end.
It catalyses the formation of a phosphodiester bond between the 3'-OH of one nucleotide and the 5'-phosphate of the next.
The DNA backbone is now continuous and intact😍.
DNA replication doesn't go on forever — it ends with the final stage of DNA replication, called termination.
The mechanisms of termination differ significantly between prokaryotes and eukaryotes due to differences in their chromosome structures (circular vs. linear).
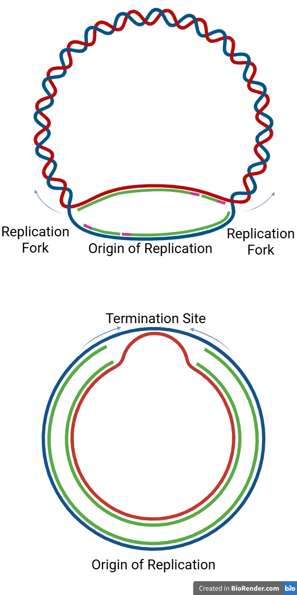
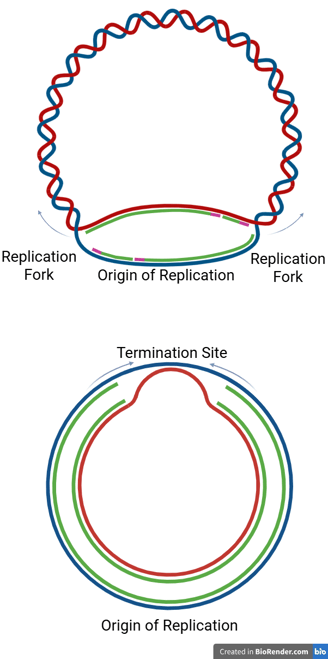
In Prokaryotes
Prokaryotic chromosomes are typically circular, and replication proceeds bidirectionally from a single origin.
The two replication forks travel in opposite directions around the chromosome until they meet at a specific termination region, usually located directly opposite the origin of replication.
This termination region contains specific DNA sequences called termination sites (or ter sites).
Tus Proteins and Fork Arrest
In E. coli, proteins called Tus (Terminus utilization substance) bind to the ter sites.
The Tus-ter complex acts like a "one-way valve" — it allows a replication fork to enter from one side but blocks it from progressing in the opposite direction.
This mechanism ensures that both forks converge and stop within the termination zone.
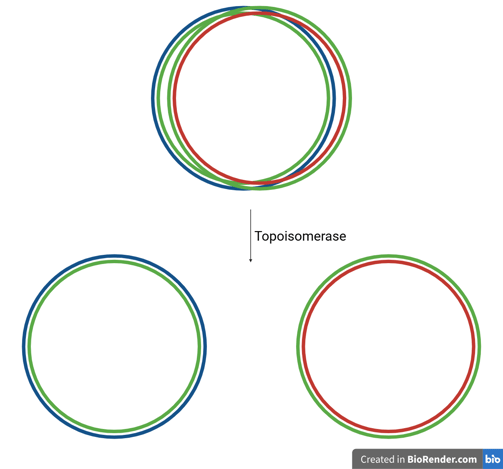
Catenanes and Topoisomerase
After replication is complete, the two circular daughter DNA molecules are often still interlinked, forming structures known as catenanes (like two interlocked rings).
These must be separated to ensure proper chromosome segregation.
The enzyme topoisomerase (specifically Topoisomerase IV in bacteria, also called DNA gyrase) plays a critical role:
It introduces a transient double-stranded break in one DNA molecule, passes the other through it, and reseals the break — effectively un-linking the catenated DNA circles.
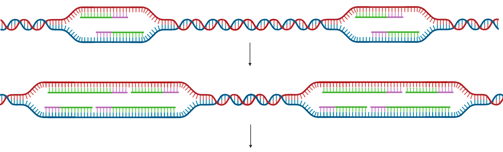
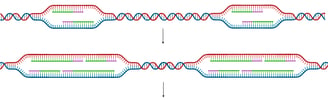

In Eukaryotes
Eukaryotic chromosomes are typically linear and contain multiple origins of replication.
With multiple origins, replication forks from adjacent origins eventually meet and fuse. When forks meet, the remaining segments of DNA are synthesised, any remaining RNA primers are removed, and nicks are ligated, just as in the elongation phase.
1.3 Termination
In Circular DNA
In Linear DNA
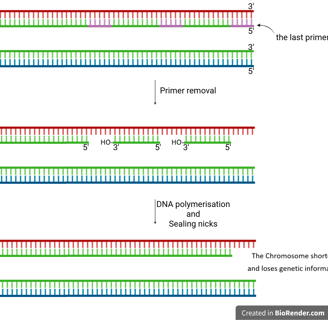
The End-Replication Problem
When the last RNA primer on the lagging strand at the very end of a linear chromosome is removed, there's no upstream DNA to provide a free 3’-OH group for DNA polymerase to fill in the gap.
This leaves a small, unreplicated region at the 5’ end of the newly synthesised lagging strand.
If left unaddressed, this problem would cause chromosomes to progressively shorten with each round of replication, ultimately leading to a loss of genetic information.
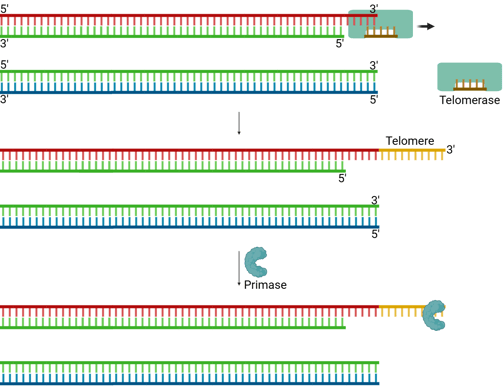
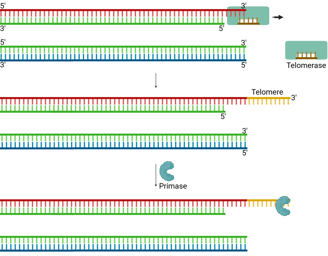
Telomeres
Eukaryotic chromosomes contain special repetitive DNA sequences at their ends, called telomeres (e.g., TTAGGG repeats in humans). These non-coding sequences protect genes from being lost during replication.
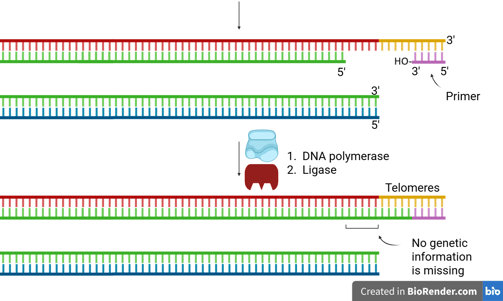
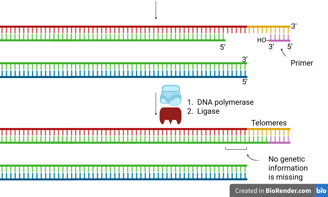
How the End-Replication Problem Is Solved
A specialized enzyme called telomerase solves the end-replication problem.
Telomerase is a reverse transcriptase (we will discuss it in the next section) that carries its own RNA template, which is complementary to the telomeric DNA sequence.
It uses this RNA template to extend the 3’ end of the parental (template) strand at the chromosome end.
This extension creates extra space for primase to lay down an RNA primer.
Then, DNA polymerase can synthesise the complementary lagging strand.
DNA ligase seals the nick, completing the strand.
This mechanism provides enough extra sequence for the replication machinery to finish copying the lagging strand, thus preventing progressive chromosome shortening.
1.4 Conclusion
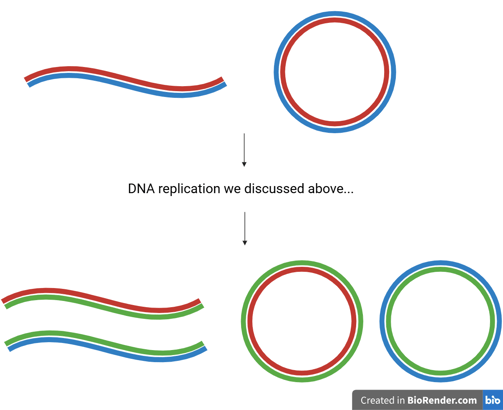
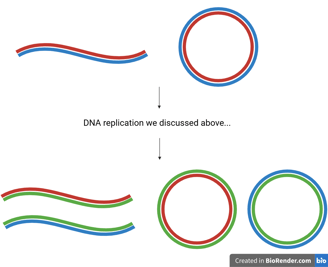
At this point, we should have a comprehensive understanding of how a double-stranded parent DNA molecule is faithfully duplicated into two double-stranded daughter molecules, each carrying identical genetic information.😎
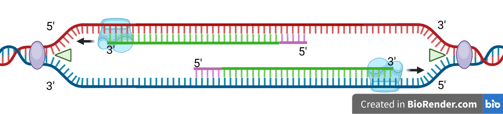
DNA replication is a semi-conservative process, meaning that each daughter DNA double helix contains:
One original (parental) strand — shown in red or blue in the figure.
One newly synthesised strand — shown in green.
Importantly, the two resulting helices retain their anti-parallel orientation, preserving the fundamental structure of DNA. This mechanism ensures genetic continuity across generations of cells, while also providing the structural basis for heredity.
References:
D. Y. Takeda and A. Dutta, DNA replication and progression through S phase, Oncogene, 2005, 24, 2827–2843.
W. Messer, The bacterial replication initiator DnaA. DnaA and, the bacterial mode to initiate DNA replication, FEMS Microbiology Reviews, 2002, 26, 355–374.
P. Ruff, R. A. Donnianni, E. Glancy, J. Oh and L. S. Symington, RPA stabilization of Single-Stranded DNA is critical for Break-Induced replication, Cell Reports, 2016, 17, 3359–3368.
Libretexts, 13.1: DNA Replication in Prokaryotes, https://bio.libretexts.org/Bookshelves/Introductory_and_General_Biology/Principles_of_Biology/02%3A_Chapter_2/13%3A_DNA_Replication/13.01%3A_DNA_Replication_in_Prokaryotes#:~:text=the%20nitrogenous%20bases-,Ligase,primers%20needed%20to%20start%20replication.
E. J. Rawdon, J. Dorier, D. Racko, K. C. Millett and A. Stasiak, How topoisomerase IV can efficiently unknot and decatenate negatively supercoiled DNA molecules without causing their torsional relaxation, Nucleic Acids Research, 2016, 44, 4528–4538.
K. Masutomi, S. Kaneko, N. Hayashi, T. Yamashita, Y. Shirota, K. Kobayashi and S. Murakami, Telomerase Activity Reconstituted in Vitro with Purified Human Telomerase Reverse Transcriptase and Human Telomerase RNA Component, Journal of Biological Chemistry, 2000, 275, 22568–22573.
© 2025 Anson Chow. All rights reserved.
Keep exploring, learning, and thinking.
Driven by curiosity, guided by strategy, fueled by passion.